- 신용등급체계공시
- home
- 신용등급체계공시
- 개인신용평점체계
- 성능지표 산출원리
성능지표 산출원리
01 K-S 통계량 (Kolmogorov-Smirnov Statistics)
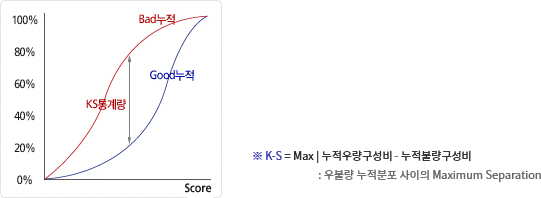
- K-S 통계량은 우량집단과 불량집단의 누적분포의 차이를 나타내는 지표로 개인신용평점모형의 변별력 평가 시 주요 판별 통계량으로 활용됩니다.
K-S 통계량이 50이상이면 우수한 모형으로 판단합니다. - 신용평점에 따른 우불량 집단의 분포차이로 누적 우량비율과 누적 불량비율 차이의 최대 값을 K-S 통계량으로 정의합니다.
02 지니(GINI) 계수
- Gini계수는 주로 소득 불평등을 측정하는 지표로 사용되는데, 소득 대신 신용평점에 따른 불량누적분포를 이용하여 신용평점모형의 변별력을 판별하는 지표로 활용됩니다.
- 누적불량 구성비를 y축으로, 누적 구성비를 x축으로 나타낸 그래프 사이의 면적의 합을 나타내며, 면적이 넓을수록 변별력이 우수한 것으로 판단이 가능합니다.
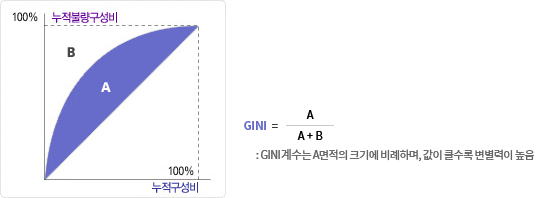
- 모형 변별력 지표로서 활용할 때는 0.6이상이면 모형의 변별력이 뛰어난 것으로 판단하게 됩니다.
03 PSI(Population Stability Index)
- PSI는 모집단의 안정성을 나타내는 지수로, 기준시점 대비 현재 분포의 차이를 나타내며 수치가 클수록 모집단의 변화가 크다는 것을 의미합니다.
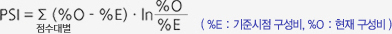
[예제] PSI 계산
| 점수대 | 기준시점 고객수 | 현재 고객수 | 기준시점 구성비(%E) | 현재 구성비(%O) | %O-%E | Ln (%O/%E) | PSI |
|---|---|---|---|---|---|---|---|
| 76~100 | 600 | 700 | 20.0% | 21.9% | 1.9% | 0.0896 | 0.0017 |
| 51~75 | 1,000 | 900 | 33.3% | 28.1% | -5.2% | -0.1699 | 0.0088 |
| 26~50 | 1,000 | 1,100 | 33.3% | 34.4% | 1.0% | 0.0308 | 0.0003 |
| 0~25 | 400 | 500 | 13.3% | 15.6% | 2.3% | 0.1586 | 0.0036 |
| 합계 | 3,000 | 3,200 | 100% | 100% | - | - | 0.0144 |



